Note: this document is subject to change as more feedback is received. Check back for updates later. This is version 1.1c.
Preamble
A critically important task in the coming months is to inspire a growing wave of people worldwide to campaign for effective practical coordination of the governance of advanced AI. That’s as an alternative to leaving the development and deployment of advanced AI to follow its present chaotic trajectory.
The messages that need to be conveyed, understood, and acted upon, are that
- The successful governance of advanced AI will result in profound benefit for everyone, whereas a continuation of the present chaotic state of affairs risks global catastrophe
- The successful governance of advanced AI isn’t some impossible dream, but lies within humanity’s grasp
- Nevertheless, real effort, real intelligence, and, yes, real coordination will be needed, so humanity can reach a world of unprecedented abundance, rather than sleepwalk into disaster.
What would have great value is a campaign slogan that conveys the above insights, and which is uplifting, unifying, easily understood, and forward-looking. The right slogan would go viral, and would galvanise people in all walks of life to take positive action.
To that end, that slogan should ideally be
- Memorable and punchy
- Emotionally resonant
- Credibly audacious
- Universally understandable
- Open-ended enough to invite participation
To be clear, that slogan should not cause panic or despair, but should put people into a serious frame of mind.
A specific proposal
After several days of online brainstorming, in which numerous ideas were presented and discussed, I now present what I consider the best option so far.
Choose coordination not chaos, so AI brings abundance for all
If there is a need for a three-word version of this, options include
- Coordination not chaos
- Choose AI abundance
Of course, what’s needed isn’t just a standalone slogan. Therefore, please find here also a sample illustrative image and, most important, a set of talking points to round out the concept.
About the image
Here’s the commentary by ChatGPT, when asked to suggest an image to illustrate this campaign slogan:
Concept: Two contrasting futures from a single branching path.
Scene:
- A wide landscape split into two diverging paths or realms — one vibrant and coordinated, the other chaotic and fragmented.
- In the coordinated half:
- A harmonious world — sustainable cities, diverse communities collaborating with AI, lush green spaces, clean tech, and open exchanges of knowledge and creativity.
- Subtle signs of AI woven into infrastructure: responsive lighting, robotic assistants, AI-powered transport.
- In the chaotic half:
- A fractured world — disconnected enclaves, pollution, conflict, neglected tech, and isolated individuals overwhelmed by noise or misinformation.
- AI appears uncontrolled — surveillance drones, malfunctioning robots, or broken screens.
Central focus:
- A group of people at the fork in the path, pointing and stepping toward the coordinated future, with calm, confident AI assistants guiding the way.
(Aside: although the actual image produced arguably needs more work, the concept described by ChatGPT is good. And it’s reassuring that the slogan, by itself, produced a flow of ideas resonant with the intended effect.)
Talking points
The talking points condensed to a single slide:
And now in more detail:
1. Humanity’s superpower: coordination
Humanity’s most important skill is sometimes said to be our intelligence – our ability to understand, and to make plans in order to achieve specific outcomes.
But another skill that’s at least as important is our ability to coordinate, that is, our ability to:
- Share insights with each other
- Operate in teams where people have different skills
- Avoid needless conflict
- Make and uphold agreements
- Accept individual constraints on our action, with the expectation of experiencing greater freedom overall.
Coordination may be informal or formal. It can be backed up by shared narratives and philosophies, by legal systems, by the operation of free markets, by councils of elders, and by specific bodies set up to oversee activities at local, regional, or international levels.
Here are some examples of types of agreements on individual constraints for shared mutual benefit:
- Speed limits for cars, to reduce the likelihood of dangerous accidents
- Limits on how much alcohol someone can drink before taking charge of a car
- Requirements to maintain good hygiene during food preparation
- Requirements to assess the safety of a new pharmaceutical before deploying it widely
- Prohibitions against advertising that misleads consumers into buying faulty goods
- Rules preventing over-fishing, or the overuse of shared “commons” resources
- Rules of various sports and games – and agreed sanctions on any cheaters
- Prohibitions against politicians misleading parliaments – and agreed sanctions on any cheaters
- Prohibitions against the abuse of children
- Rules governing the conduct of soldiers – which apply even in times of war
- Restrictions on the disposal of waste
- Rules governing ownership of dangerous breeds of dog
- Rules governing the spread of dangerous materials, such as biohazards
Note that coordination is often encouraging rather than restrictive. This includes
- Prizes and other explicit incentives
- Implicit rewards for people with good reputation
- Market success for people with good products and services
The fact that specific coordination rules and frameworks have their critics doesn’t mean that the whole concept of coordination should be rejected. It just means that we need to keep revising our coordination processes. That is, we need to become better at coordinating.
2. Choosing coordination, before chaos ensues
When humanity uncovers new opportunities, it can take some time to understand the implications and to create or update the appropriate coordination rules and frameworks for these opportunities:
- When settlers on the island of Mauritius discovered the dodo – a large, flightless bird – they failed to put in place measures to prevent that bird becoming extinct only a few decades later
- When physicists discovered radioactivity, it took some time to establish processes to reduce the likelihood that researchers would develop cancer due to overexposure to dangerous substances
- Various new weapons (such as chemical gases) were at first widely used in battle zones, before implicit and then explicit agreement was reached not to use such weapons
- Surreptitious new doping methods used by athletes to gain extra physical advantage result, eventually, in updates to rules on monitoring and testing
- Tobacco was widely used – and even encouraged, sometimes by medical professionals – before society decided to discourage its use (against the efforts of a formidable industry)
- Similar measures are now being adopted, arguably too slowly, against highly addictive food products that are thought to cause significant health problems
- New apps and online services which spread hate speech and other destabilising misinformation surely need some rules and restrictions too, though there is considerable debate over what form of governance is needed.
However, if appropriate coordination is too slow to be established, or is too weak, or exists in words only (without the backup of meaningful action against rules violators), the result can be chaos:
- Rare animals are hunted to extinction
- Fishing stocks are depleted to the extent that the livelihood of fishermen is destroyed
- Economic transactions have adverse negative externalities on third parties
- Dangerous materials, such as microplastics, spread widely in the environment
- No-one is sure what rules apply in sports, and which rules will be enforced
- Normal judiciary processes are subverted in favour of arbitrary “rule of the in-group”
- Freedoms previously enjoyed by innovative new start-ups are squelched by the so-called “crony capitalism” of monopolies and cartels linked to the ruling political regime
- Literal arms races take place, with ever-more formidable weapons being rushed into use
- Similar races take place to bring new products to market without adequate safety testing
Groups of people who are (temporarily) faring well from the absence of restraints on their action are likely to oppose rules that alter their behaviour. That’s the experience of nearly every industry whose products or services were discovered to have dangerous side-effects, but where insiders fought hard to suppress the evidence of these dangers.
Accordingly, coordination does not arise by default. It needs explicit choice, backed up by compelling analysis, community engagement, and strong enforcement.
3. Advanced AI: the promise and the peril
AI could liberate humanity from many of our oldest problems.
Despite huge progress of many kinds over the centuries, humans still often suffer grievously on account of various aspects of our nature, our environment, our social norms, and our prevailing philosophies. Specifically, we are captive to
- Physical decline and aging
- Individual and collective mental blindspots and cognitive biases (“stupidity”)
- Dysfunctional emotions that render us egotistical, depressed, obsessive, and alienated
- Deep psychosocial tendencies toward divisiveness, xenophobia, deception, and the abuse of power
However, if developed and used wisely, advanced AI can enable rejuvenation and enhancement of our bodies, minds, emotions, social relations, and our links to the environment (including the wider cosmos):
- AI can accelerate progress with nanotech, biotech, and cognotech
- In turn, these platform technologies can accelerate progress with abundant low-cost clean energy, nutritious food, healthcare, education, security, creativity, spirituality, and the exploration of marvellous inner and outer worlds
In other words, if developed and used wisely, advanced AI can set humanity free to enjoy much better qualities of life:
However, if developed and used unwisely, advanced AI is likely to cause catastrophe:
- Via misuse by people who are angry, alienated, or frustrated
- Via careless use by people who are naive, overconfident, or reckless
- Via AI operating beyond our understanding and control
- Via autonomous AI adopting alien modes of rationality and alien codes of ethics
The key difference between these two future scenarios is whether the development and use of AI is wisely steered, or instead follows a default path of deprioritising any concerns about safety:
- The default path involves AI whose operation is opaque, which behaves deceptively, which lacks moral compass, which can be assigned to all kinds of tasks with destructive side-effects, and which often disregards human intentions
- Instead, if AI is wisely harnessed, it will deliver value as a tool, but without any intrinsic agency, autonomy, volition, or consciousness
- Such a tool can have high creativity, but won’t use that creativity for purposes opposed to human wellbeing
To be clear, there is no value in winning a reckless race to be the first to create AI with landmark new features of capability and agency. Such a race is a race to oblivion, also known as a suicide race.
4. The particular hazards of advanced AI
The dangers posed by AI don’t arise from AI in isolation. They involve AI in the hands of fallible, naïve, over-optimistic humans, who are sometimes driven by horrible internal demons. It’s AI summoned and used, not by the better angels of human nature, but by the darker corners of our psychology.
Although we humans are often wonderful, we sometimes do dreadful things to each other – especially when we have become angry, alienated, or frustrated. Add in spiteful ideologies of resentment and hostility, and things can become even uglier.
Placing technology in the hands of people in their worst moments can lead to horrific outcomes. The more powerful the technology, the bigger the potential abomination:
- The carnage of a frenzied knife attack or a mass shooting (where the technology in question ranges from a deadly sharp knife to an automatic rifle)
- The chaos when motor vehicles are deliberately propelled at speed into crowds of innocent pedestrians
- The deaths of everyone on board an airplane, when a depressed air pilot ploughs the craft into a mountainside or deep into an ocean, in a final gesture of defiance to what they see as an unfair, uncaring world
- The destruction of iconic buildings of a perceived “great satan”, when religious fanatics have commandeered jet airliners in service of the mental pathogen that has taken over their minds
- The assassination of political or dynastic rivals, by the mixing of biochemicals that are individually harmless, but which in combination are frightfully lethal
- The mass poisoning of commuters in a city subway, when deadly chemicals are released at the command of a cult leader who fancies himself as the rightful emperor of Japan, and who has beguiled clearly intelligent followers to trust his every word.
How does advanced AI change this pattern of unpleasant possibilities? How is AI a significantly greater threat than earlier technologies? In six ways:
- As AI-fuelled automation displaces more people from their work (often to their surprise and shock), it predisposes more people to become bitter and resentful
- AI is utilised by merchants of the outrage industrial complex, to convince large numbers of people that their personal circumstance is more appalling than they had previously understood, that a contemptible group of people over there are responsible for this dismal turn of events, and that the appropriate response is to utterly defeat those deplorables
- Once people are set on a path to obtain revenge, personal recognition, or just plain pandemonium, AIs can make it much easier for them to access and deploy weapons of mass intimidation and mass destruction
- Due to the opaque, inscrutable nature of many AI systems, the actual result of an intended outrage may be considerably worse even than what the perpetrator had in mind; this is similar to how malware sometimes causes much more turmoil than the originator of that malware intended
- An AI with sufficient commitment to the goals it has been given will use all its intelligence to avoid being switched off or redirected; this multiplies the possibility that an intended local outrage might spiral into an actual global catastrophe
- An attack powered by fast-evolving AI can strike unexpectedly at core aspects of the infrastructure of human civilization – our shared biology, our financial systems, our information networks, or our hair-trigger weaponry – exploiting any of the numerous fragilities in these systems.
And it’s not just missteps from angry, alienated, frustrated people, that we have to worry about. We also need to beware potential cascades of trouble triggered by the careless actions of people who are well-intentioned, but naive, over-optimistic, or simply reckless, in how they use AI.
The more powerful the AI, the greater the dangers.
Finally, the unpredictable nature of emergent intelligence carries with it another fearsome possibility. Namely, a general intelligence with alien thinking modes far beyond our own understanding, might decide to adopt an alien set of ethics, in which the wellbeing of eight billion humans merits only a miniscule consideration.
That’s the argument against simply following a default path of “generate more intelligence, and trust that the outcome is likely to be beneficial for humanity”. It’s an argument that should make everyone pause for thought.
5. A matter of real urgency
How urgent is the task of improving global coordination of the governance of advanced AI?
It is sometimes suggested that progress with advanced AI is slowing down, or is hitting some kind of “wall” or other performance limit. There may be new bottlenecks ahead. Or diseconomies of scale may supersede the phenomenon of economies of scale which has characterised AI research over the last few years.
However, despite these possibilities, the case remains urgent:
- Even if one approach to improving AI runs out of steam, huge numbers of researchers are experimenting with promising new approaches, including approaches that combine current state-of-the-art methods into new architectures
- Even if AI stops improving, it is already dangerous enough to risk incidents in which large numbers of people are harmed
- Even if AI stops improving, clever engineers will find ways to take better advantage of it – thereby further increasing the risks arising, if it is badly configured or manifests unexpected behaviour
- There is no guarantee that AI will actually stop improving; making that assumption is too much of a risk to take on behalf of the entirety of human civilisation
- Even if it will take a decade or longer for AI to reach a state in which it poses true risks of global catastrophe, it may also take decades for governance systems to become effective and practical; the lesson from ineffective efforts to prevent runaway climate change are by no means encouraging here
- Even apart from the task of coordinating matters related to advanced AI, human civilisation faces other deep challenges that also require effective coordination on the global scale – coordination that, as mentioned, is currently failing on numerous grounds.
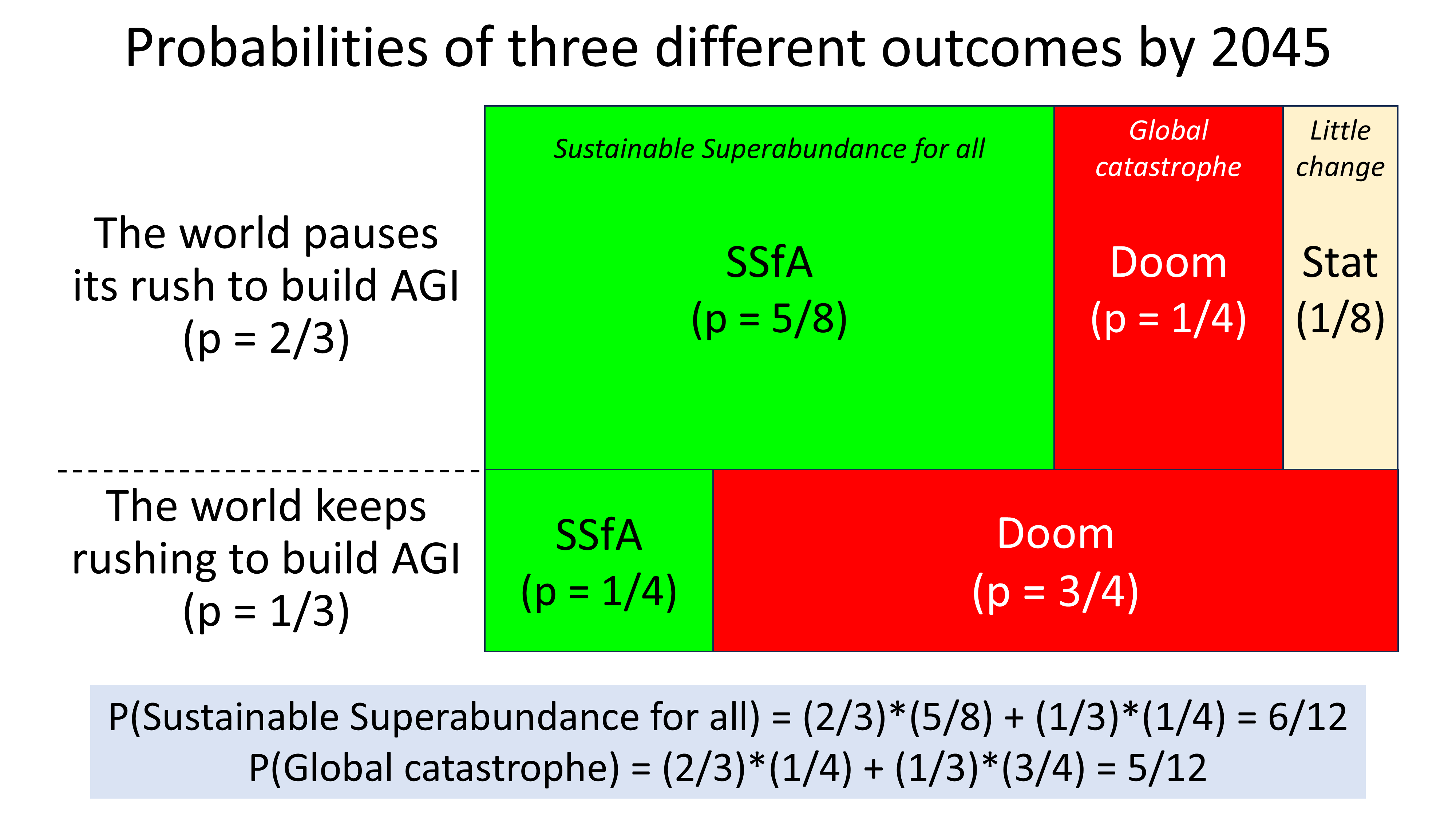
So, there’s an imperative to “choose coordination not chaos” independent of considering the question of whether advanced AI will lead to abundance or to a new dark age.
6. A promising start and an unfortunate regression
Humanity actually made a decent start in the direction of coordinating the development of advanced AI, at the Global AI Safety Summits in the UK (November 2023) and South Korea (May 2024).
Alas, the next summit in that series, in Paris (February 2025) was overtaken by political correctness, by administrivia, by virtue signalling, and, most of all, by people with a woefully impoverished understanding of the existential opportunities and risks of advanced AI. Evidently, the task of raising true awareness needs to be powerfully re-energised.
There’s still plenty of apparent global cooperation taking place – lots of discussions and conferences and summits, with people applauding the fine-sounding words in each other’s speeches. “Justice and fairness, yeah yeah yeah!” “Transparency and accountability, yeah yeah yeah!” “Apple pie and blockchain, yeah yeah yeah!” “Intergenerational intersectionality, yeah yeah yeah!”
But the problem is the collapse of effective, practical global cooperation, regarding the hard choices about which aspects of advanced AI should be promoted, and which should be restricted.
Numerous would-be coordination bodies are struggling with the same set of issues:
- It’s much easier to signal virtue than to genuinely act virtuously.
- Too many of the bureaucrats who run these bodies are out of their depth when it comes to understanding the existential opportunities and risks of advanced AI.
- Seeing no prospect of meaningful coordination, many of the big tech companies invited to participate do so in a way that obfuscates the real issues while maintaining their public image as “trying their best to do good”.
- The process is undermined by people who can be called “reckless accelerationists” – people who are willing to gamble that the chaotic processes of creating advanced AI as quickly as possible will somehow result in a safe, beneficial outcome (and, in some cases, these accelerationists would even take a brief perverted pleasure if humanity were rendered extinct by a non-sentient successor AI species); the accelerationists don’t want the public as a whole to be in any position to block their repugnant civilisational Russian roulette.
How to address this dilemma is arguably the question that should transcend all others, regarding the future of humanity.
7. Overcoming the obstacles to effective coordination of the governance of advanced AI
To avoid running aground on the same issues as in the past, it’s important to bear in mind the five main reasons for the failure, so far, of efforts to coordinate the governance of advanced AI. They are:
- Fear that attempts to control the development of AI will lead to an impoverished future, or a future in which the world is controlled by people from a different nation (e.g. China)
- Lack of appreciation of the grave perils of the current default chaotic course
- A worry that any global coordination would lurch toward a global dictatorship, with its own undeniable risks of catastrophe
- The misapprehension that, without the powers of a global dictatorship, any attempts at global coordination are bound to fail, so they are a waste of time
- The power that Big Tech possesses, allowing it to ignore half-hearted democratic attempts to steer their activities.
In broad terms, these obstacles can be overcome as follows:
- Emphasising the positive outcomes, including abundance, freedom, and all-round wellbeing – and avoiding the psychologically destabilising outlook of “AI doomers”
- Increasing the credibility and relatability of scenarios in which ungoverned advanced AI leads to catastrophe – but also the credibility and relatability of scenarios in which humanity’s chaotic tendencies can be overcome
- Highlighting previous examples when the governance of breakthrough technology was at least partially successful, rather than developers being able to run amok – examples such as genetic recombination therapies, nuclear proliferation, and alternatives to the chemicals that caused the hole in the ozone layer
- Demonstrating the key roles that decentralised coordination should play, as a complement to the centralised roles that nation states can play
- Clarifying how global coordination of advanced AI can start with small agreements and then grow in scale, without individual countries losing sovereignty in any meaningful way.
8. Decentralised reputation management – rewards for good behaviour
What is it that leads individuals to curtail their behaviour, in conformance with a set of standards promoted in support of a collaboration?
In part, it is the threat of sanction or control – whereby an individual might be fined or imprisoned for violating the agreed norms.
But in part, it is because of reputational costs when standards are ignored, side-lined, or cheated. The resulting loss of reputation can result in declining commercial engagement or reduced social involvement. Cheaters and freeloaders risk being excluded from future new opportunities available to other community members.
These reinforcement effects are strongest when the standards received community-wide support while being drafted and adopted – rather than being imposed by what could be seen as outside forces or remote elites.
Some reputation systems operate informally, especially in small or local settings. For activities with a wider involvement, online rating systems can come into their own. For example, consider the reputation systems for reviews of products, in which the reputation of individual reviewers changes the impact of various reviews. There are similarities, as well, to how webpages are ranked when presented in response to search queries: pages which have links from others with high reputation tend in consequence to be placed more prominently in the listing.
Along these lines, reputational ratings can be assigned, to individuals, organisations, corporations, and countries, based on their degree of conformance to agreed principles for trustworthy coordinated AI. Entities with poor AI coordination ratings should be shunned. Other entities that fail to take account of AI coordination ratings when picking suppliers, customers, or partners, should in turn be shunned too. Conversely, entities with high ratings should be embraced and celebrated.
An honest, objective assessment of conformance to the above principles should become more significant, in determining overall reputation, than, for example, wealth, number of online followers, or share price.
Emphatically, the reputation score must be based on actions, not words – on concrete, meaningful steps rather than behind-the-scenes fiddling, and on true virtue rather than virtue-signalling. Accordingly, deep support should be provided for any whistleblowers who observe and report on any cheating or other subterfuge.
In summary, this system involves:
- Agreement on which types of AI development and deployment to encourage, and which to discourage, or even ban
- Agreement on how to assign reputational scores, based on conformance to these standards
- Agreement on what sanctions are appropriate for entities with poor reputations – and, indeed, what special rewards should flow to entities with good reputations.
All three elements on this system need to evolve, not under the dictation of central rulers, but as a result of a grand open conversation, in which ideas rise to the surface if they make good sense, rather than being shouted with the loudest voice.
That is, decentralised mechanisms have a vital role to play in encouraging and implementing wise coordination of advanced AI. But centralised mechanisms have a vital role too, as discussed next.
9. Starting small and then growing in scale
If someone continues to ignore social pressures, and behaves irresponsibly, how can the rest of society constrain them? Ultimately, force needs to be applied. A car driver who recklessly breaks speed limits will be tracked down, asked to stop, and if need be, will be forced off the road. A vendor who recklessly sells food prepared in unhygienic conditions will be fined, forbidden to set up new businesses, and if need be, will be imprisoned. Scientists who experiment with highly infectious biomaterials in unsafe ways will lose their licence and, if need be, their laboratories will be carefully closed down.
That is, society is willing to grant special powers of enforcement to some agents acting on behalf of the entire community.
However, these special powers carry their own risks. They can be abused, in order to support incumbent political leaders against alternative ideas or opposition figures.
The broader picture is as follows: Societies can fail in two ways: too little centralised power, and too much centralised power.
- In the former case, societies can end up ripped apart by warring tribes, powerful crime families, raiding gangs from neighbouring territories, corporations that act with impunity, and religious ideologues who stamp their contentious visions of “the pure and holy” on unwilling believers and unbelievers alike
- In the latter case, a state with unchecked power diminishes the rights of citizens, dispenses with the fair rule of law, imprisons potential political opponents, and subverts economic flows for the enrichment of the leadership cadre.
The healthiest societies, therefore, possess both a strong state and a strong civil society. That’s one meaning of the celebrated principle of the separation of powers. The state is empowered to act, decisively if needed, against any individual cancers that would threaten the health of the community. But the state is informed and constrained by independent, well-organised judiciary, media, academia, credible opposition parties, and other institutions of civil society.
It should be the same with the governance of potential rogue or naïve AI developers around the world. Via processes of decentralised deliberations, taking account of input from numerous disciplines, agreement should be reached on which limits are vital to be observed.
Inevitably, different participants in the process will have different priorities for what the agreements should contain. In some cases, these limits imposed might vary between different jurisdictions, within customisation frameworks agreed globally. But there should be clear acceptance that some ways of developing or deploying advanced AIs need to be absolutely prevented. To prevent the agreements from unravelling at the earliest bumps in the road, it will be important that agreements are reached unanimously among the representatives of the jurisdictions where the most powerful collections of AI developers are located.
The process to reach agreement can be likened to the deliberations of a jury in a court case. In most cases, jury members with initially divergent opinions eventually converge on a conclusion. In cases when the process becomes deadlocked, it can be restarted with new representative participants. With the help of expert facilitators – themselves supported by excellent narrow AI tools – creative new solutions can be introduced for consideration, making an ultimate agreement more likely.
To start with, these agreements might be relatively small in scope, such as “don’t place the launch of nuclear weapons under AI control”. Over time, as confidence builds, the agreements will surely grow. That’s because of the shared recognition that so much is at stake.
Of course, for such agreements to be meaningful, there needs to be a reliable enforcement mechanism. That’s where the state needs to act – with the support and approval of civil society.
Within entire countries that sign up to this AI coordination framework, enforcement is relatively straightforward. The same mechanisms that enforce other laws can be brought to bear against any rogue or naïve AI developers.
The challenging part is when countries fail to sign up to this framework, or do so deceitfully, that is, with no intention of keeping their promises. In such a case, it will fall to other countries to ensure conformance, via, in the first place, measures of economic sanction.
To make this work, all that’s necessary is that a sufficient number of powerful countries sign up to this agreement. For example, if the G7 do so, plus China and India, along with countries that are “bubbling under” G7 admission (like Australia, South Korea, and Brazil), that should be sufficient. Happily, there are many AI experts in all these countries who have broad sympathies to the kinds of principles spelt out in this document.
As for potential maverick nations such as Russia and North Korea, they will have to weigh up the arguments. They should understand – like all other countries – that respecting such agreements is in their own self-interest. To help them reach such an understanding, appropriate pressure from China, the USA, and the rest of the world should make a decisive difference.
This won’t be easy. At this pivotal point of history, humanity is being challenged to use our greatest strength in a more profound way than ever before – namely, our ability to collaborate despite numerous differences. On reflection, it shouldn’t be a surprise that the unprecedented challenges of advanced AI technology will require an unprecedented calibre of human collaboration.
If we fail to bring together our best talents in a positive collaboration, we will, sadly, fulfil the pessimistic forecast of the eighteenth-century Anglo-Irish statesman Edmund Burke, paraphrased as follows: “The only thing necessary for the triumph of evil is that good men fail to associate, and do nothing”. (The original quote is this: “No man … can flatter himself that his single, unsupported, desultory, unsystematic endeavours are of power to defeat the subtle designs and united cabals of ambitious citizens. When bad men combine, the good must associate; else they will fall, one by one, an unpitied sacrifice in a contemptible struggle.”) Or, updating the wording slightly, “The only thing necessary for chaos to prevail is that good men fail to coordinate wisely”.
A remark from the other side of the Atlantic from roughly the same time, attributed to Benjamin Franklin, conveys the same thought in different language: “We must… all hang together, or assuredly we shall all hang separately”.
10. Summary: The nucleus of a wider agreement, and call to action
Enthusiasm for agreements to collaborate on the governance of advanced AIs will grow as a set of insights are understood more widely and more deeply. These insights can be stated as follows:
- It’s in the mutual self-interest of every country to constrain the development and deployment of what could become catastrophically dangerous AI; that is, there’s no point in winning what could be a reckless suicide race to create powerful new types of AI before anyone else
- The major economic and humanitarian benefits that people hope will be delivered by the hasty development of advanced AI (benefits including all-round abundance, as well as solutions to various existential risks), can in fact be delivered much more reliably by AI systems that are constrained, and by development systems that are coordinated rather than chaotic
- A number of attractive ideas already exist regarding potential policy measures (regulations and incentives) which can be adopted, around the world, to prevent the development and deployment of what could become catastrophic AI – for example, measures to control the spread and use of vast computing resources, or to disallow AIs that use deception to advance their goals
- A number of good ideas also exist and are ready to be adopted around the world, regarding options for monitoring and auditing, to ensure the strict application of the agreed policy measures – and to prevent malign action by groups or individuals that have, so far, failed to sign up to these policies, or who wish to cheat them
- All of the above can be achieved without any detrimental loss of individual sovereignty: the leaders of countries can remain masters within their own realms, as they desire, provided that the above basic AI coordination framework is adopted and maintained
- All of the above can be achieved in a way that supports evolutionary changes in the AI coordination framework as more insight is obtained; in other words, this system can (and must) be agile rather than static
- Even though this coordination framework is yet to be fully agreed, there are plenty of ideas for how it can be rapidly developed, so long as that project is given sufficient resources, and the best brains from multiple disciplines are encouraged to give it their full attention
- Ring-fencing sufficient resources to further develop this AI coordination framework, and associated reputational ratings systems, should be a central part of every budget
- Reputational ratings that can be assigned, based on the above principles, will play a major role in altering behaviours of the many entities involved in the development and deployment of advanced AI.
Or, to summarise this summary: Choose coordination not chaos, so AI brings abundance for all.
Now is the time to develop these ideas further (by all means experiment with ways to simplify their expression), to find ways to spread them more effectively, and to be alert for newer, better insights that arise from the resulting open global conversation.
Other ideas considered
The ideas presented above deserve attention, regardless of which campaign slogans are adopted.
For comparison, here is a list of other possible campaign slogans, along with reservations that have been raised about each of them:
- “Pause AI” (too negative)
- “Control AI” (too negative)
- “Keep the Future Human” (insufficiently aspirational)
- “Take Back Control from Big Tech” (doesn’t characterise the problem accurately enough)
- “Safe AI for sustainable superabundance” (overly complex concepts)
- “Choose tool AI instead of AGI” (lacks a “why”)
- “Kind AI for a kinder world” (perhaps too vague)
- “Narrow AI to broaden humanity’s potential” (probably too subtle)
- “Harness AI to liberate humanity” (terminology overly scholarly or conceptual).
Also for comparison, consider the following set of slogans from other fields:
- “Yes we can” (Barack Obama, 2008)
- “Make America great again” (Donald Trump, 2016)
- “Take back control” (UK Brexit slogan)
- “Think different” (Apple)
- “Because you’re worth it” (L’Oréal)
- “Black lives matter”
- “Make love, not war”
- “For the Many, Not the Few” (Jeremy Corbyn, 2017)
- “Get Brexit done” (Boris Johnston, 2019)
- “Not Me. Us” (Bernie Sanders, 2020)
- “We shall fight them on the beaches” (Winston Churchill, 1940)
- “It’s Morning Again in America” (Ronald Reagan, 1984)
- “Stay Home. Save Lives” (Covid-19 messaging)
- “Clunk click every trip” (encouraging the use of seat belts in cars)
- “We go to the moon, not because it is easy, but because it is hard” (JFK, 1962)
- “A microcomputer on every desk and in every home running Microsoft software” (Bill Gates, 1975)
- “To organise the world’s information and make it universally accessible and useful” (Google, 1998)
- “Accelerating the world’s transition to sustainable energy” (Tesla, 2016)
- “Workers of the world, unite – you have nothing to lose but your chains” (Karl Marx, 1848)
- “From each according to his ability, to each according to his needs” (Karl Marx, 1875)
Comments are welcome on any ideas in this article. Later revisions of this article may incorporate improvements arising from these comments.
Postscript
New suggestions under consideration, following the initial publication of this article:
- “Harness AI now” (Robert Whitfield)